Профессия data scientist
Содержание:
- Введение в Data Science и Big Data
- Что знают и умеют дата-сайентисты
- Зачем Data Science бизнесу
- Дата-сайентисты в облаках
- Как им стать
- К вам всегда будут обращаться с любыми вопросами о данных
- Дата-сайентист внедряет модель в продукт или в бизнес
- Кто такой Data Scientist и чем он занимается?
- *2020: Академия больших данных MADE и HeadHunter выяснили, как меняется спрос на Data Scientist в России
- Дата-аналитик
- В каких случаях становятся специалистом по Data Science?
- Как дела обстоят у нас
- Требования к специалисту
- Чем занимается Data Scientist?
- Как он это делает?
- Будущее Data Science
Введение в Data Science и Big Data
- В чем разница между Data Scientist и Data Engineer
- Где учиться: курсы, магистерские программы и др.
- Лайфхаки как найти работу
- Введение в профессию Big Data от популярного сервиса Антирабство
- Обзор всех профессий, связанных с Big Data
- Какие навыки нужны для попадания в профессию
Подборка видео с неформальных встреч DataTalks на Youtube.
- Сжатое и яркое объяснение того, как данные полностью изменили бизнес-стратегию
- Спикер: вице-президент Boston Consulting Group Филип Эванс
- Есть расшифровка лекции на русском
Введение в искусственный интеллект и машинное обучение

- Лекция Байрама Аннакова, основателя App-in-the-Air и Empatika
- Очень занимательное и наглядное описание того, как развивался искусственный интеллект
Машинное обучение
- Вторая лекция Байрама Аннакова
- Типы машинного обучения и методов создания искусственного интеллекта
- Множество кейсов и практических советов
Машинный интеллект и машинное обучение
- Лекция Андрея Себранта,директора по маркетингу сервисов Яндекса
- Увлекательное введение в тему с множеством ярких примеров
Нейросети: доступно о сложном
Очень подробная и простая для понимания статья о том, как работают нейронные сети и Deep Learning
Что знают и умеют дата-сайентисты
Вот начальный список навыков, знаний и умений, которые нужны любому дата-сайентисту для старта в работе.
Математическая логика, линейная алгебра и высшая математика. Без этого не получится построить модель, найти закономерности или предсказать что-то новое.
Есть те, кто говорит, что это всё не нужно, и главное — писать код и красиво делать отчёты, но они лукавят. Чтобы обучить нейронку, нужна математика и формулы; чтобы найти закономерности в данных — нужна математика и статистика; чтобы сделать отчёт на основе большой выборки данных — ну, вы поняли. Математика рулит.
Знание машинного обучения. Работа дата-сайентиста — анализ данных огромного размера, и вручную это сделать нереально. Чтобы было проще, они поручают это компьютерам. Поручить такую задачу — значит настроить готовую нейросеть или обучить свою. Поручить программисту обычно это нельзя — слишком много нужно будет объяснить и проконтролировать.
Программирование на Python и R. Мы уже писали, что Python — идеальный язык для машинного обучения и нейросетей. На нём можно быстро написать любую модель для первоначальной оценки гипотезы, поиска общих данных или простой аналитики.
R — язык программирования для статического анализа. Если вам нужно прикинуть, как лайки на странице зависят от количества просмотров или до какого места читатель гарантированно долистывает статью (чтобы поставить туда баннер), — R вам поможет. Но если вы не знаете математику — не поможет.
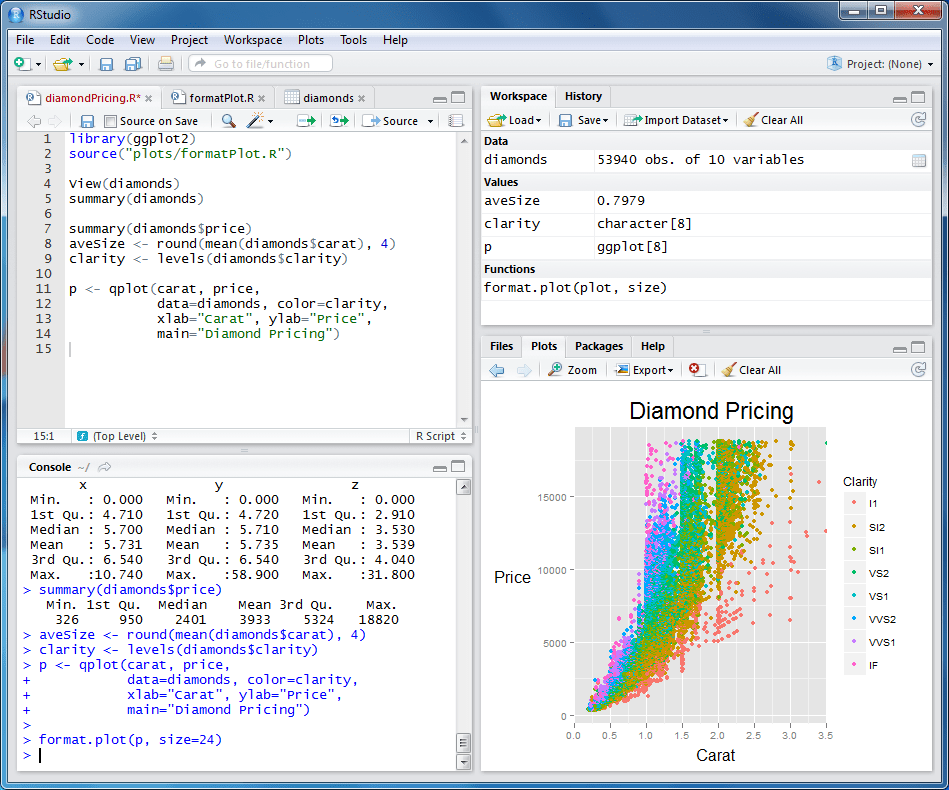 R и статистика в действии. Картинка с Хабра.
R и статистика в действии. Картинка с Хабра.
Умение получать и визуализировать данные. Не всем дата-сайентистам везёт настолько, что они сразу получают готовые наборы данных для обработки. Чаще всего они сами должны выяснить, где, откуда, как и сколько брать данных. Здесь обычные программисты им уже могут помочь — спарсить сайт, выкачать большую базу данных или настроить сбор статистики на сервере.
Второй важный навык в этой профессии — умение наглядно показать результаты работы. Какой толк в графиках, если никто, кроме автора, не понимает, что там нарисовано? Задача дата-сайентиста — представить данные наглядным образом, чтобы зрителю было легче сделать нужный вывод.
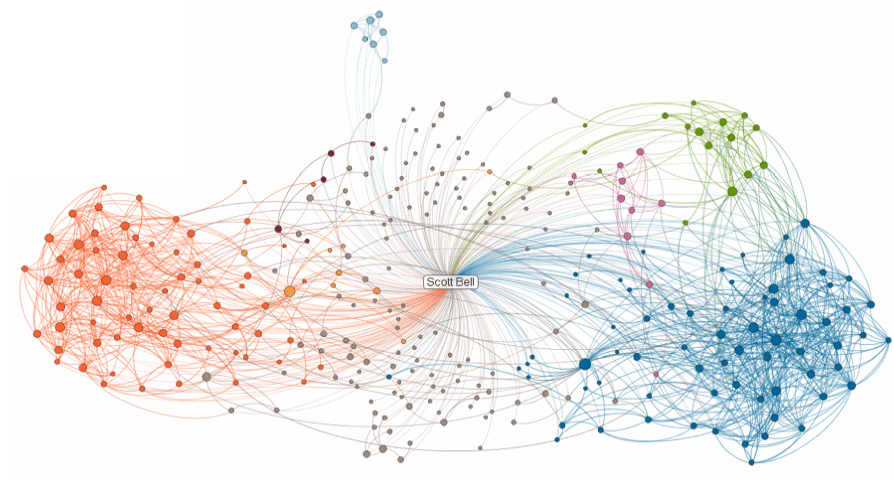 Связи в твиттере некоего Скотта Белла. Явно видны несколько разных групп фолловеров, которые мало пересекаются между собой. Это и есть наглядное представление данных.
Связи в твиттере некоего Скотта Белла. Явно видны несколько разных групп фолловеров, которые мало пересекаются между собой. Это и есть наглядное представление данных.
Зачем Data Science бизнесу
Компании используют Data Science вне зависимости от размера бизнеса, показывает статистика Kaggle (профессиональная соцсеть специалистов по работе с данными). А по подсчетам IDC и Hitachi, 78% предприятий подтверждают, что количество анализируемой и используемой информации в последнее время значительно возросло. Бизнес понимает, что неструктурированная информация содержит очень важные для компании знания, способные повлиять на результаты бизнеса, отмечают авторы исследования.

Индустрия 4.0
Роман Нестер — РБК: «Коммерческие данные — это кровь интернета»
Причем это касается самых разных сфер экономики. Вот лишь несколько примеров отраслей, которые используют Data Science для решения своих задач:
- онлайн-торговля и развлекательные сервисы: рекомендательные системы для пользователей;
- здравоохранение: прогнозирование заболеваний и рекомендации по сохранению здоровья;
- логистика: планирование и оптимизация маршрутов доставки;
- digital-реклама: автоматизированное размещение контента и таргетирование;
- финансы: скоринг, обнаружение и предотвращение мошенничества;
- промышленность: предиктивная аналитика для планирования ремонтов и производства;
- недвижимость: поиск и предложение наиболее подходящих покупателю объектов;
- госуправление: прогнозирование занятости и экономической ситуации, борьба с преступностью;
- спорт: отбор перспективных игроков и разработка стратегий игры.
И это лишь самый краткий и поверхностный список использования Data Science. Количество различных кейсов с использованием «науки о данных» увеличивается с каждым годом в геометрической прогрессии.
Каждый интернет-пользователь и просто потребитель ежедневно десятки раз сталкивается с продуктами и решениями, в которых применяются инструменты Data Science. К примеру, аудио-сервис Spotify использует их, чтобы лучше подбирать треки для пользователей в соответствии с их предпочтениями. То же самое можно сказать о предложении фильмов и сериалах на видео-стримингах, таких как Netflix. А в Uber науку о данных рассматривают как инструмент для предиктивной аналитики, прогнозирования спроса, улучшения и автоматизации всех продуктов и клиентского опыта.

Экономика инноваций
Что такое Big Data и почему их называют «новой нефтью»
Конечно, дата-сайентисты не могут в точности предсказать будущее компании и учесть абсолютно все возможные риски. «Все модели неправильные, но некоторые из них полезны», — иронизировал по этому поводу британский статистик Джордж Бокс. Тем не менее, инструменты Data Science служат хорошей поддержкой для компаний, которые хотят принимать более информированные и обоснованные решения о своем будущем.
Дата-сайентисты в облаках
Облегчить и ускорить работу по сбору данных, построению и развертыванию моделей помогают специальные облачные платформы. Именно облачные платформы для машинного обучения стали самым актуальным трендом в Data Science. Поскольку речь идет о больших объемах информации, сложных ML-моделях, о готовых и доступных для работы распределенных команд инструментах, то дата-сайентистами понадобились гибкие, масштабируемые и доступные ресурсы.
Именно для дата-сайентистов облачные провайдеры создали платформы, ориентированные на подготовку и запуск моделей машинного обучения и дальнейшую работу с ними. Пока таких решений немного и одно из них было полностью создано в России. В конце 2020 года компания Sbercloud представила облачную платформу полного цикла разработки и реализации AI-сервисов — ML Space. Платформа содержит набор инструментов и ресурсов для создания, обучения и развертывания моделей машинного обучения — от быстрого подключения к источникам данных до автоматического развертывания обученных моделей на динамически масштабируемых облачных ресурсах SberCloud.

Футурология
«Я бы вакцинировал троих на миллион». Интервью с нейросетью GPT-3
Сейчас ML Space — единственный в мире облачный сервис, позволяющий организовать распределенное обучение на 1000+ GPU. Эту возможность обеспечивает собственный облачный суперкомпьютер SberCloud — «Кристофари». Запущенный в 2019 году «Кристофари» является сейчас самым мощным российским вычислительным кластером и занимает 40 место в мировом рейтинге cуперкомпьютеров TOP500
Платформу уже используют команды разработчиков экосистемы Сбера. Именно с ее помощью было запущено семейство виртуальных ассистентов «Салют». Для их создания с помощью «Кристофари» и ML Space было обучено более 70 различных ASR- моделей (автоматическое распознавание речи) и большое количество моделей Text-to-Speech. Сейчас ML Space доступна для любых коммерческих пользователи, учебных и научных организаций.
«ML Space – это настоящий технологический прорыв в области работы с искусственным интеллектом. По нескольким ключевым параметрам ML Space уже превосходит лучшие мировые решения. Я считаю, что сегодня ML Space одна из лучших в мире облачных платформ для машинного обучения. Опытным дата-сайентистам она предоставляет новые удобные инструменты, возможность распределенной работы, автоматизации создания, обучения и внедрения ИИ-моделей. Компаниям и организациям, не имеющим глубокой ML-экспертизы, ML Space дает возможность впервые использовать искусственный интеллект в своих продуктах, приложениях и рабочих процессах», — уверен Отари Меликишвили, лидер продуктового вправления AI Cloud, компании SberCloud.
Облака помогают рынку все шире использовать платформы для работы с данными, предлагая безграничные вычислительные мощности, подтверждают аналитики Mordor Intelligence.
По мнению экспертов из Anaconda, потребуется время, чтобы бизнес и сами специалисты созрели для широкого использования инструментов DS и смогли получить результаты. Но прогресс уже очевиден. «Мы ожидаем, что в ближайшие два-три года Data Science продолжит двигаться к тому, чтобы стать стратегической функцией бизнеса во многих отраслях», — прогнозирует компания.
Как им стать
Учеба обязательна для этой профессии. Причем учиться надо много, долго и основательно. Для начала надо освоить азы математики, статистики и информатики, а дальше изучить языки программирования, лучше начать с Python.
На блоге iklife.ru собраны лучшие курсы по Python для начинающих и опытных программистов, которые будут полезны при освоении должности Data Scientist.
Также рекомендую вам прочитать следующие книги:
- Брендан Тирни, Джон Келлехер “Наука о данных”
- Кирилл Еременко “Работа с данными в любой сфере”
- Уэс Маккинни “Python и анализ данных”
Куда пойти учиться
Лучшее обучение – это онлайн-обучение. Платформы Skillbox, Нетология, GeekBrains, SkillFactory, ProductStar и Stepik предлагают свои обучающие программы:
- Профессия Data Scientist
- Data Scientist
- Data Science с нуля
Ознакомиться с полным перечнем курсов для Data Scientist можно на нашем блоге.
Уточню, что на этом учеба не должна заканчиваться. Data Scientist – это такая профессия, которая предполагает непрерывное обучение. Даже если вы уже работаете, периодически повышать свой уровень надо обязательно. К тому же выбор достаточно широк – это и онлайн-курсы, и тренинги, и конференции.
Где найти работу
Сложно сказать, где именно искать работу по этой профессии. Не из-за того, что мало мест, а, наоборот, потому что нет такой сферы бизнеса, где нельзя было бы применить талант этого специалиста. Ему доступна как работа в офисе, так и удаленно на дому.
Он востребован в таких областях деятельности как:
- IT-сфера,
- медицина,
- банковские структуры,
- СМИ,
- торговля,
- политика,
- транспортные компании,
- страховые фирмы,
- сельское хозяйство,
- наука,
- метеослужбы.
Как я уже говорила, Data Scientist нужен во многих сферах, где необходимы прогнозы, анализ рисков и поведения клиентов. Поэтому список можно дополнить.
Перед откликом на вакансию надо подготовить резюме. В нем сосредоточиться в первую очередь нужно на математических и IT-навыках, опыте работе, успешных проектах и достижениях. Описание должно получиться кратким, лаконичным и простым. Специалисту надо прикрепить портфолио к резюме.
Учтите, что вакансии на эту должность не всегда называются именно “Data Scientist”. Работодатели могут написать, что требуется IT-аналитик, специалист по анализу систем, аналитик Big Data.
К вам всегда будут обращаться с любыми вопросами о данных
Вернемся к предыдущему пункту, где я говорил о том, что вам придется делать все, чтобы угодить влиятельным людям. Эти же люди часто не понимают, что именно значит «дата-сайентист». Для них вы будете экспертом в области всего, что касается данных. Ваши коллеги будут думать так же. Для них вы будете хорошо разбираться в Spark, Hadoop, Hive, Pig, SQL, Neo4J, MySQL, Python, R, Scala, Tensorflow, A/B Testing, NLP. (Кстати, будьте осторожны, когда увидите такие характеристики в каком-то описании вакансии. Скорее всего, руководство такого предприятия готово нанять любого специалиста, надеясь, что он решит все их проблемы с данными).

GIF: Medium
Порой очень сложно донести до людей, что вы не знаете всего. Вы будете переживать, что упадете в глазах других, потому что у вас еще недостаточно опыта в индустрии.
Дата-сайентист внедряет модель в продукт или в бизнес
Примеры выше сосредоточены вокруг первых этапов проекта Data Science, но последний посвящён завершающей стадии. Предположим, у вас есть лучшая автоматизированная платформа выбора модели с потрясающей точностью… но что она будет делать? Чтобы ответить на этот вопрос, необходим специалист в Data Science.
-
Автоматизация может зайти очень далеко, поэтому специалист знает, куда поместить результаты — в приложение, на сайт и т. д.
-
Дата-сайентисты должны знать, с какой частотой обучать модель, показывать результаты или делать прогнозы — во многих случаях это обсуждается, когда изучаются данные и определяются задачи.
-
Специалисты понимают, как эффективнее обобщить сложные результаты для заинтересованных сторон. Даже если результаты хорошо обобщены AutoML, отвечая на вопросы клиентов, заинтересованных сторон и руководства человек, например специалист в Data Science, окажется полезнее.
Кто такой Data Scientist и чем он занимается?
Говоря простыми словами, это специалист по анализу данных. Он собирает их, объединяет в базы, ищет и анализирует закономерности и на этой основе создает модели, которые помогают принимать те или иные решения. Чаще всего они востребованы в следующих сферах: ИТ, телеком, банки и финансы, консалтинг, маркетинг, научные исследования.
Какие задачи они решают:
- Создание рекомендательных систем.
- Формирование прогнозов, например, на рынках акций.
- Создание скоринговых систем, которые принимают решения на основе анализа большого объема данных. Например, выдать кредит клиенту или нет.
- Выявление аномалий в различных системах. Например, для автоматической блокировки подозрительных банковских операций.
-
Персонализированный маркетинг. Формирование уникальных предложений для клиентов, акций, скидок.
Чтобы проще понять, чем занимается Data Scientist, разберем пример рекомендательного алгоритма. Многие музыкальные сервисы на основе статистики прослушиваний могут предлагать пользователям другие треки, которые им понравятся. Алгоритм, по которому работает эта программа, создает специалист по анализу больших данных.
Все больше компаний собирают различные базы данных, которые используются для разных целей. Поэтому востребованность специалистов растет. Им предлагают хорошие зарплаты, о чем расскажем ниже.
Мы разобрались, кто такой Data Scientist и что это за профессия. Пора поговорить о преимуществах и недостатках данной работы.
*2020: Академия больших данных MADE и HeadHunter выяснили, как меняется спрос на Data Scientist в России
16 июля 2020 года Академия больших данных MADE от Mail.ru Group и российская платформа онлайн-рекрутинга HeadHunter (hh.ru) составили портреты российских специалистов по анализу данных (Data Science) и машинному обучению (Machine Learning). Аналитики выяснили, где они живут и что умеют, а также чего ждут от них работодатели и как меняется спрос на таких профессионалов.
Академия MADE и HeadHunter (hh.ru) проводят исследование уже второй год подряд. На этот раз эксперты проанализировали 10 500 резюме и 8100 вакансий. По оценкам аналитиков, специалисты по анализу данных — одни из самых востребованных на рынке. В 2019 году вакансий в области анализа данных стало больше в 9,6 раза, а в области машинного обучения – в 7,2 раза, чем в 2015 году. Если сравнивать с 2018 годом, количество вакансий специалистов по анализу данных увеличилось в 1,4 раза, по машинному обучению – в 1,3 раза.

Активнее других специалистов по большим данным ищут ИТ-компании (на их долю приходится больше трети – 38% – открытых вакансий), компании из финансового сектора (29% вакансий), а также из сферы услуг для бизнеса (9% вакансий).
Такая же ситуация и в сфере машинного обучения. Но здесь перевес в пользу ИТ-компаний еще очевиднее – они публикуют 55% вакансий на рынке. Каждую десятую вакансию размещают компании из финансового сектора (10% вакансий) и сферы услуг для бизнеса (9%).
С июля 2019 года по апрель 2020 года резюме специалистов по анализу данных и машинному обучению стало больше на 33%. Первые в среднем размещают 246 резюме в месяц, вторые – 47.

Самый популярный навык — владение Python. Это требование встречается в 45% вакансий специалистов по анализу данных и в половине (51%) вакансий в области машинного обучения.
Также работодатели хотят, чтобы специалисты по анализу данных знали SQL (23%), владели интеллектуальным анализом данных (Data Mining) (19%), математической статистикой (11%) и умели работать с большими данными (10%).
Работодатели, которые ищут специалистов по машинному обучению, наряду со знанием Python ожидают, что кандидат будет владеть C++ (18%), SQL (15%), алгоритмами машинного обучения (13%) и Linux (11%).
В целом предложение на рынке Data Science соответствует спросу. Среди самых распространенных навыков специалистов по анализу данных – владение Python (77%), SQL (48%), анализом данных (45%), Git (28%) и Linux (21%). При этом владение Python, SQL и Git – навыки, которые практически одинаково часто встречаются в резюме специалистов любого уровня. Опытных специалистов отличают развитые навыки анализа данных, в том числе интеллектуального (Data Analysis и Data Mining).
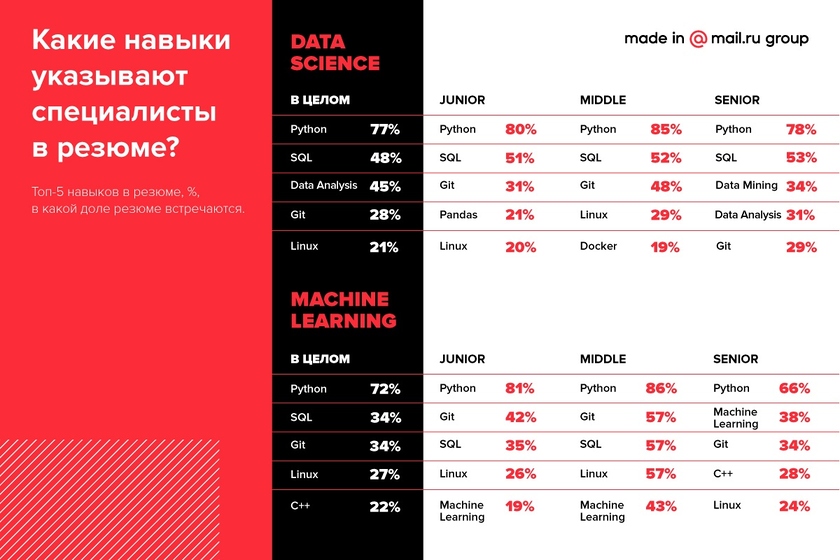
У специалистов по машинному обучению в топе такие навыки, как владение Python (72%), SQL (34%), Git (34%), Linux (27%) и С++ (22%).
На долю Москвы приходится больше половины (65%) вакансий специалистов по в сфере анализа данных и ровно половина вакансий специалистов в области машинного обучения. На втором месте Санкт-Петербург: 15% вакансий специалистов в сфере анализа данных и 18% вакансий в области машинного обучения — в этом городе.
По сравнению с первым полугодием 2019 года в июле 2019 года – апреле 2020 года доля вакансий специалистов по анализу данных в Москве несколько возросла — с 60% до 65%.
Что касается соискателей, больше половины из них также находятся в Москве: 63% специалистов по анализу данных и 53% специалистов по машинному обучению. Вторая строчка – тоже за Санкт-Петербургом (16% и 19% резюме соответственно).
Дата-аналитик
Если вам нравится описывать данные, выявлять в них тренды, анализировать полученные результаты и, наконец, визуализировать их для заказчика, вам подойдет позиция дата-аналитика. Скорее всего, в ходе работы вы будете много общаться с людьми и двигаться по карьерной лестнице быстрее, чем это делают дата-сайентисты.
С кем вам предстоит работать?
Вы будете часто взаимодействовать с представителями компаний, которые заказывают обработку и визуализацию данных. Иногда вы будете встречаться в офисе, иногда общение будет происходить онлайн — в электронной почте, Slack и Jira. По моему опыту, вам предстоит регулярно общаться с людьми и заниматься в основном аналитикой, при этом инженерных задач и работы с продуктом будет меньше.
С кем нужно будет делиться выводами?
Скорее всего, с теми же самыми людьми. Однако, если у вас есть менеджер, общение частично будет происходить через него. Также бывают ситуации, когда дата-аналитик получает задачу, выполняет ее и затем самостоятельно представляет результаты заказчикам. Для составления отчетов часто используются такие инструменты, как Tableau, Google Data Studio, Power BI и Salesforce. В основном они работают с доступными источниками, такими как CSV-файлы, но иногда приходится создавать более сложные SQL-запросы к базам данных.
С какой скоростью нужно выполнять задачи?
Вы будете работать над проектами значительно быстрее, чем дата-сайентисты. Запросы, материалы и аналитические данные приходят регулярно, и на их основе нужно создавать отчеты. Дата-аналитику, как правило, не нужно строить модели и делать прогнозы — его задачи более ситуативные и описательные, поэтому их можно выполнять быстрее.

Фото: Gorodenkoff / Shutterstock
В каких случаях становятся специалистом по Data Science?
- Когда нравится анализ и систематизация данных и есть интерес к передовым технологиям — дата-сайентисты работают с искусственным интеллектом, нейросетями и большими данными.
- Когда хочется заниматься исследованиями и наукой на качественно новом уровне.
- Когда есть опыт в обычной разработке и есть желание освоить больший набор инструментов и заниматься масштабными проектами.
- Когда на текущей работе мало перспектив, хочется освоить перспективное направление и больше зарабатывать.

Глеб Синяков
аналитик-разработчик в «Тинькофф»
Всех, кто приходит в Data Science, можно разделить на четыре потока. Есть те, кто становятся дата-сайентистами после профессионального образования, но в университетах таких курсов пока немного. Также есть люди технических и научных профессий, которые хотят найти более перспективную работу с большой зарплатой. Третий поток — разработчики, которые устают от скучного программирования и ищут интересные задачи. Есть специалисты, которые начинали с нуля: если у новичков есть самодисциплина и интерес к большим данным, то они становятся хорошими дата-сайентистами. Наконец, есть те, к кому Data Science приходит сам, например к биоинформатикам.
Подробнее о том, чем занимается Глеб Синяков, читайте в рассказе о его профессии.
Как дела обстоят у нас
Мы создаем систему городской мобильности с человеческим отношением к пассажирам и водителям. И хотим сделать это отраслевым стандартом. Хотим встречать и провожать пассажиров в аэропорты и на вокзалы; доставлять важные документы по указанным адресам быстрее курьеров; сделать так, чтобы на такси было не страшно отправить ребёнка в школу или девушку домой после свидания, даем возможность выбрать транспорт — каршеринг, такси или самокат. И даже если нашим пассажиром является котик, то ему должно быть максимально комфортно.
У нас есть большой отдел эффективности платформы (или Marketplace), где в каждом из направлений работают специалисты по обработке и анализу данных.
-
Ценообразование: правильный и правдоподобный предрасчет цены для клиента на предстоящую поездку. Мы разрабатываем алгоритмы, которые тонко настраивают наши цены под специфические региональные и временные условия, а также помогают нам держать вектор оптимального ценового роста и развития
-
Клиентские мотивации: помогают нам привлекать новых клиентов, удерживать старых и делать нашу цену самой привлекательной на рынке. Основное направление — это разработка алгоритма оптимального распределения бюджета на скидки клиентам для достижения максимального количества поездок. Мы стремимся создать выгодное предложение для каждого клиента, поддержать и ускорить наш рост
-
Водительские мотивации: одна из главных задач Ситимобил — забота о водителях. Наши алгоритмы создают для них среду, в которой каждый работает эффективно и зарабатывает много. Мы стремимся разработать подход, позволяющий стимулировать водителей к выполнению поездок там, где другие алгоритмы не справляются: возмещаем простой на линии, если нет заказов, и гарантируем стабильность завтрашнего дня для привлечения всё новых и новых водителей.
-
Динамическое ценообразование: главная задача направления — гарантировать возможность уехать на такси в любое время и в любом месте. Достигается это за счет кратковременного изменения цен, когда желающих уехать больше, чем водителей в определенной гео-зоне.
-
Распределение заказов: эффективные алгоритмы назначения водителей на заказ уменьшают длительность ожидания и повышают заработок водителей. Задача этого направления — создать масштабируемые механизмы назначения, превосходно работающие как в целом по городам, так и в разрезе каждого тарифа.
-
Исследование эффективности маркетплейсов: центральное аналитическое направление, задачей которого является анализ эффективного баланса между количеством водителей на линии и пассажирами.
-
ГЕО сервисы: эффективное использование геоданных помогает различным командам эффективно настраивать свои алгоритмы, которые напрямую зависят от качества этих данных. Мы стремимся создавать такие модели, сервисы и алгоритмы, которые не только повышают качество маршрутизации и гео-поиска, но и напрямую воздействуют на бизнес, а также клиентский опыт.
Требования к специалисту
Специалист по данным неразрывно связан с Data Science – наукой о данных. Она находится на пересечении нескольких направлений: математики, статистики, информатики и экономики. Следовательно, специалисты должны понимать и интересоваться каждой из этих наук.
Кроме этого, Data Scientist должен знать:
- Языки программирования для того, чтобы писать на них код. Самые распространенные – это SAS, R, Java, C++ и Python.
- Базы данных MySQL и PostgreSQL.
- Технологии и инструменты для представления отчетов в графическом формате.
- Алгоритмы машинного и глубокого обучения, которые созданы для автоматизации повторяющихся процессов с помощью искусственного интеллекта.
- Как подготовить данные и сделать их перевод в удобный формат.
- Инструменты для работы с Big Data: Hadoop, MapReduce, Apache Hive, Apache Kafka, Apache Spark.
- Как установить закономерности и видеть логические связи в системе полученных сведений.
- Как разработать действенные бизнес-решения.
- Как извлекать нужную информацию из разных источников.
- Английский язык для чтения профессиональной литературы и общения с зарубежными клиентами.
- Как успешно внедрить программу.
- Область деятельности организации, на которую работает.
Помимо того, что специалист по данным должен обладать аналитическим и математическим складом ума, он также должен быть:
- трудолюбивым,
- настойчивым,
- скрупулезным,
- внимательным,
- усидчивым,
- целеустремленным,
- коммуникабельным.
Хочу отметить, что гуманитариям достичь высот в этой профессии будет крайне тяжело. Только при большом желании можно пробовать осваивать данную стезю.
Чем занимается Data Scientist?
Пропустите этот пункт, если вы это уже знаете.
Ну, исходя из моего опыта работы Data Scientist в нескольких компаниях вроде GoDaddy, HERE, и GoGo, Data Scientist решает задачи с помощью машинного обучения в Big Data. Несколько примеров: предсказать вероятность отказа клиента от подписки, выявить ошибки в данных, вычислительный специальный анализ гигабайт и терабайт данных, кластеризация клиентов по смысловым группам, аналитика текста при определении тем в расшифровках чатов онлайн поддержки, расчет предполагаемых доходов, и так далее до бесконечности.
Как Data Scientist вам придется продираться через множество разных проблем. Чтобы быть компетентным, нужно иметь хорошее знание математики, статистики и программирования. Вам нужно знать, когда и какие именно техники и алгоритмы использовать в зависимости от проблемы и имеющихся данных. Ну и наконец, вам часто придется представлять результаты использования соответствующих методов руководителям и другим людям, не связанным с этой сферой.
Кроме того, как Data Scientist вам нужно будет постоянно учиться и подстраиваться
Так как эта сфера очень быстро развивается, важно всегда держать руку на пульсе и быть в курсе новых методик. Даже сейчас я трачу много времени на обучение
Как он это делает?
Задачи аналитику ставит владелец продукта или проектный менеджер. Например, разработать и внедрить какую-то модель на производстве. Владелец продукта оценивает сложность задачи и собирает необходимую для решения команду: дата-сайентист, фронтенд- и бэкенд-разработчики, дизайнер и так далее. Специалистов каждой специальности может быть несколько, а может и ни одного, в зависимости от задачи и предполагаемого решения.
Расскажу, как мы в СИБУРе строим модель. Допустим, мы хотим предсказать факт брака детали по данным с датчиков на производстве.

- Первый этап — сбор данных. Аналитик готовит данные для анализа: выгружает из различных источников, обрабатывает пропуски в данных (значения, которые должны быть, но отсутствуют). На выходе получается таблица.
- Второй этап — предварительный анализ. Бывает полезно нарисовать разные графики и внимательно их изучить. В шутку некоторые аналитики называют это методом «пристального взгляда». Это может дать интересные соображения, помочь выявить странности и много чего еще, что поможет в решении задачи.
- Третий этап — построение признакового описания. Поясню, что это. У нас уже есть таблица с данными от датчиков, но в большинстве случаев этого мало. Необходимо самостоятельно рассчитать некоторые величины, которые могут помочь классифицировать деталь как бракованную.
Например, может быть недостаточно измерить температуру в разных точках детали датчиками. Есть смысл рассчитать среднее арифметическое по всем этим датчикам, а также максимальную, минимальную температуру, разброс температур и много чего еще.
Таким образом, рассчитывая и добавляя новые величины, мы расширяем признаковое описание нашей детали. Именно это описание (набор чисел для каждой детали) мы используем для построения модели. В нашем примере моделью будет являться некоторый алгоритм, который пытается восстановить зависимость между признаковым описанием детали и ответом (есть брак или нет).
В итоге модель обычно представляет из себя код, который может прочитать данные (например, из таблицы Excel или из базы данных), построить предсказания и записать результат (опять-таки в таблицу или базу данных).
Но в таком виде модель еще нельзя считать законченной. Модель должна быть внедрена и работать у заказчика.

Если говорить о конкретных проектах, в которых я принимал участие в СИБУРе, то первой была задача разработки модели для производства изобутилена, которая должна была предсказывать коксование. На решетках реактора образуются углеродные отложения, которые могут решетки повредить.
Помимо самой модели, необходимо было сделать визуализацию предсказаний, которая должна обновляться в реальном времени после каждого пересчета предсказаний, а также реализовать регулярную загрузку актуальных данных в базу для расчета предсказаний. Этой задачей я занимался один, при этом периодически пользовался помощью коллег в некоторых вопросах, связанных с производственной системой хранения данных.
В этом проекте я выступаю уже больше как архитектор и разработчик фреймворка, отвечающего за все вычисления. В то время как мой коллега, тоже аналитик данных, но с профильным химическим образованием, больше решает задачи моделирования, в том числе с использованием химии и физики, хотя это разделение обязанностей весьма условно. Также в этом проекте участвуют фронтенд-разработчики, так как визуальная часть нашего решения достаточно сложна.
Будущее Data Science
У Data Science большие перспективы, и вот почему:
Экспоненциальный рост объема данных в мире
Люди проводят все больше времени в интернете, бизнес диджитализируется, начинает развиваться интернет вещей (IoT). К 2025 году объем данных в мире увеличится почти в 3 раза, до 181 Зеттабайта (секстилиона байтов). Еще в 2010 году в мире было всего 2 Зб.
Рост рынка Data Science
Гигантские объемы данных ведут к росту количества Data Science-стартапов и вакансий специалистов по анализу данных. По прогнозам, до 2027 года рынок будет в среднем расти на 27% в год. Больше всего решений требуется в маркетинге и рекламе, логистике, финансах и поддержке пользователей.
Развитие технологий искусственного интеллекта
Эксперты утверждают, что в ближайшем будущем на улицах городов массово появятся беспилотные автомобили, а домашняя техника будет подключена к интернету вещей (IoT). Автономные автомобили используют машинное обучение для анализа дорожной ситуации и безопасного передвижения. IoT позволит получать данные миллиардов новых устройств и использовать искусственный интеллект в системах «умного дома».
Все это ведет к повышению спроса на дата-сайентистов. Так, количество вакансий в этой сфере в России за три года выросло на 433%. Спрос на специалистов превышает предложение, а это увеличивает их зарплату: junior data scientist после года обучения в среднем получает от 120 тыс. рублей, а после трех лет опыта — от 250 тыс. рублей.
Курс
Data Scientist
Специалисты Data Science нужны во всех сферах бизнеса — получите востребованную профессию и станьте одним из них. Дополнительная скидка 5% по промокоду BLOG.
Узнать больше



