Все что вы (не) хотели знать о data science
Содержание:
- Программирование: что и как учить?
- Что Data Scientist и Data Engineer могут делать в одной компании?
- Как лучше хранить данные, если вы дата-сайентист
- Жизненный цикл Data Science
- ? №1. Профессия Data Scientist от Skillbox
- Плюсы и минусы профессии
- Этап 6
- Машинное Обучение
- Как мы отбирали курсы?
- Чем отличается аналитик Big Data от исследователя данных
- Образование в области Data Science: ничего невозможного нет
- Где используется Data Science?
- Вывод изображения
Программирование: что и как учить?
Что такое SQL и зачем его учить?
SQL является стандартом для получения данных в нужном виде из разных баз данных. Это тоже своеобразный язык программирования, который дополнительно к своему основному языку используют многие программисты. Большинство самых разных баз данных использует один и тот же язык с относительно небольшими вариациями.
SQL простой, потому что он «декларативный»: нужно точно описать «запрос» как должен выглядеть финальный результат, и всё! — база данных сама покажет вам данные в нужной форме. В обычных «императивных» языках программирования нужно описывать шаги, как вы хотите чтобы компьютер выполнил вашу инструкцию. C SQL намного легче, потому что достаточно только точно понять что вы хотите получить на выходе.
Сам язык программирования — это ограниченный набор команд.
Когда вы будете работать с данными — даже аналитиком, даже необязательно со знанием data science, — самой первой задачей всегда будет получить данные из базы данных. Поэтому SQL надо знать всем. Даже веб-аналитики и маркетологи зачастую его используют.
Как учить SQL:
Наберите в Гугле «sql tutorial» и начните учиться по первой же ссылке. Если она вдруг окажется платной, выберете другую. По SQL полно качественных бесплатных курсов.
На русском языке тоже полно курсов. Выбирайте бесплатные.
Главное — выбирайте курсы, в которых вы можете сразу начать прямо в браузере пробовать писать простейшие запросы к данным. Только так, тренируясь на разных примерах, действительно можно выучить SQL.
На изучение достаточно всего лишь от 10 часов (общее понимание), до 20 часов (уверенное владение большей частью всего необходимого).
Почему именно Python?
В первую очередь, зачем учить Python. Возможно, вы слышали что R (другой популярный язык программирования) тоже умеет очень многое, и это действительно так. Но Python намного универсальнее. Мало сфер и мест работы, где Python вам не сможет заменить R, но в большинстве компаний, где Data Science можно делать с помощью Python, у вас возникнут проблемы при попытке использования R. Поэтому — точно учите Python. Если вы где-то услышите другое мнение, скорее всего, оно устарело на несколько лет (в 2015г было совершенно неясно какой язык перспективнее, но сейчас это уже очевидно).
У всех других языков программирования какие-либо специализированные библиотеки для машинного обучения есть только в зачаточном состоянии.
Как учить Python
Основы:
Прочитать основы и пройти все упражнения с этого сайта можно за 5-40 часов, в зависимости от вашего предыдущего опыта.
После этого варианты (все эти книги есть и на русском):
-
Learning Python, by Mark Lutz (5 издание). Существует и на русском.
Есть много книг, которые сразу обучают использованию языка в практических задачах, но не дают полного представления о детальных возможностях языка.
Эта книга, наоборот, разбирает Python досконально. Поэтому по началу её чтение будет идти медленнее, чем аналоги. Но зато, прочтя её, вы будете способны разобраться во всём.
Я прочёл её почти целиком в поездах в метро за месяц. А потом сразу был готов писать целые программы, потому что самые основы были заложены в pythontutor.ru, а эта книга детально разжевывает всё.
В качестве практики берите, что угодно, когда дочитаете эту книгу до 32 главы, и решайте реальные примеры (кстати, главы 21-31 не надо стараться с первого раза запоминать детально. Просто пробежите глазами, чтобы вы понимали что вообще Python умеет).
Не надо эту книгу (и никакую другую) стараться вызубрить и запомнить все детали сразу. Просто позже держите её под рукой и обращайтесь к ней при необходимости.
Прочитав эту книгу, и придя на первую работу с кучей опытных коллег, я обнаружил, что некоторые вещи знаю лучше них.
-
Python Crash Course, by Eric Matthes
Эта книга проще написана и отсеивает те вещи, которые всё-таки реже используются. Если вы не претендуете быстрее стать высоко-классным знатоком Python — её будет достаточно.
-
Automate the Boring Stuff with Python
Книга хороша примерами того, что можно делать с помощью Python. Рекомендую просмотреть их все, т.к. они уже похожи на реальные задачи, с которыми приходится сталкиваться на практике, в том числе специалисту по анализу данных.
Какие трудозатраты?
Путь с нуля до уровня владения Python, на котором я что-то уже мог, занял порядка 100ч. Через 200ч я уже чувствовал себя уверенно и мог работать над проектом вместе с коллегами.
(есть бесплатные программы — трекеры времени, некоторым это помогает для самоконтроля)
Что Data Scientist и Data Engineer могут делать в одной компании?
У исследователя данных и дата-инженера обычно разные цели. Первый непосредственно решает запросы бизнеса: для этого он проверяет гипотезы и строит прогнозные модели. Второй отвечает за оптимальное и надежное хранение данных, их преобразование, а также за быстрый и удобный доступ к ним. Это позволяет дата-сайентисту работать с корректными и актуальными данными. Компании, которые хотят использовать Data Science для развития своего бизнеса, могут нанимать и дата-инженера, и дата-сайентиста.
Пример: в онлайн-магазине бытовой техники каждый раз, когда посетитель сайта нажимает на тот или иной товар, создается новый элемент данных.
Дата-инженер может собрать эти данные и сохранить в удобном для доступа формате. Дата-сайентист получает данные о том, какие клиенты купили те или иные товары, и использует эту информацию так, чтобы предсказать вариант идеального предложения для каждого нового посетителя сайта.
Пример: работа в платной онлайн-библиотеке. Если компания хочет узнать, какие пользователи тратят больше денег, им нужны компетенции и дата-сайентиста, и дата-инженера. Инженер соберет информацию из логов сервера и журналов событий сайта и создаст пайплайн, который соотносит данные с конкретным пользователем. Затем инженеру нужно будет обеспечить хранение полученной информации в базе данных так, чтобы ее можно было без труда запросить. После этого дата-сайентист сможет проанализировать действия пользователей сайта и узнать особенности поведения тех, кто тратит больше денег.
Как лучше хранить данные, если вы дата-сайентист
Обычно Аркадий работает с небольшими датасетами и хранит их в файлах от 50 до 100 Мб. Но с новым проектом к нему пришел большой набор данных, и Аркадий решил как обычно сложить его в csv-файл, который получился объемом 13 Гб. И здесь начинаются проблемы.
Такой файл сложно передать кому-то из коллег: вы будете очень долго ждать, пока он загрузится в Slack или Google Drive. А еще он может вообще не открыться на компьютере. Или формат такого файла плохо доходит до прода: объем данных растет с каждым днем и файл разрастается.
Что же можно с этим сделать? Посмотрим, как хранят файлы разработчики.
-
Они используют базы данных, оптимизированные под свои задачи и под тот объем данных, который у них есть.
-
Валидируют форматы данных при загрузке.
-
Поддерживают отказоустойчивость сервисов и баз данных, которые к ним подключены.
-
Заранее думают о возможностях масштабирования. То есть сразу прогнозируют, насколько объем данных вырастет через год, и нужно ли будет переделывать архитектуру с нуля, или у них будет возможность масштабироваться до нужного объема.
Конечно, дата-сайентистам не всегда нужно делать отказоустойчивые сервисы, но тем не менее, они могут подсмотреть некоторые штуки, которые облегчат работу.
Мы уже поняли, что сохранять все в csv-формате — не вариант. Такой файл не влезет в RAM среднестатистического компьютера, а скорость чтения явно превысит 2 минуты. В этом случае нет никакой оптимизации, валидации форматов, отказоустойчивости и масштабируемости.

Попробуем разделить этот файл по отдельным партициям. Например, найти колонку с маленькой вариативностью данных, по которой можно разделить их и сложить в отдельные файлы. После этого мы сможем обрабатывать отдельные файлы под необходимые задачи. Так мы решаем проблему масштабируемости, но размер файлов все равно остается большим.
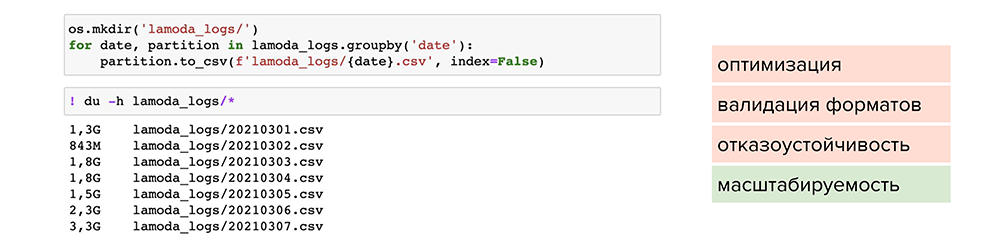
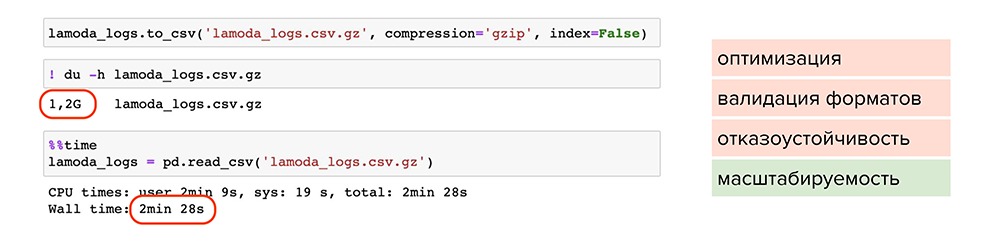
Теперь попробуем сжать файлы. Например, можно воспользоваться обычной утилитой сжатия для одного файла gzip. Она доступна в pandas, нужно лишь при сохранении указать ее в параметре , и файл станет весить 1,2 Гб вместо 13 Гб. Но читается он также 2 минуты. Делаем вывод, что такой способ мало подходит для оптимизации, хотя масштабируемость присутствует — файлы стали занимать меньше места на диске.
Попробуем улучшить результат. Например, можно использовать parquet — это специальный формат сжатия или, более умными словами, партиционированная бинарная колоночная сериализация для табличных данных. Он позволит работать с каждым типом данных в каждой колонке отдельно: например, сжимать числовые данные одним способом, текстовые или строковые данные — другим способом, и таким образом оптимизировать как хранение информации, так и чтение.
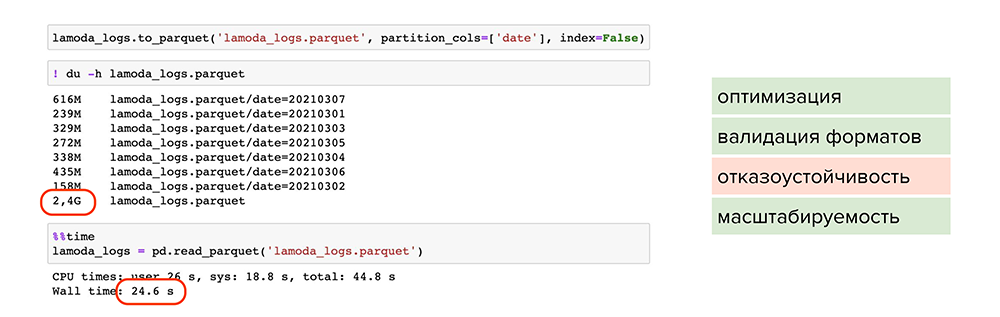
С применением parquet:
-
Большой объем данных стал весить 2,4 Гб и читаться за 24 секунды. Файлы оптимально сжаты, поделены на партиции и у каждого есть метаданные.
-
Происходит валидация форматов, поскольку parquet работает с каждым форматом колонки отдельно и проверяет их при записи. Вероятность записать ошибочные данные снижается.
-
Присутствует масштабируемость, поскольку мы пишем данные в разные партиции и сжимаем их.
Однако мы не победили один пункт — отказоустойчивость.
Чтобы покрыть все пункты, можно обратиться к специальным фреймворкам и базам данных. Например, подойдут ClickHouse или Hadoop, особенно, если это продакшн-решения или повторяющиеся истории.
Жизненный цикл Data Science
Ниже приведен краткий обзор основных этапов жизненного цикла, который позволяет ответить на вопрос о том, что такое Data Science?:

Жизненный цикл Data Science
Фаза 1 — Открытие: перед началом проекта важно понять различные спецификации, требования, приоритеты и необходимый бюджет. Вы должны обладать способностью задавать правильные вопросы
Здесь вы оцениваете, есть ли у вас необходимые ресурсы с точки зрения людей, технологии, времени и данных для поддержки проекта. На этом этапе вам также необходимо создать бизнес-задачу и сформулировать первоначальные гипотезы (IH) для тестирования.
Фаза 2 — Подготовка данных: на этом этапе вам нужна аналитическая «песочница», в которой вы можете выполнять аналитику на протяжении всего проекта. Перед моделированием вам необходимо исследовать и предварительно обработать данные. Кроме того, вы будете выполнять ETLT (extract, transform, load and transform), чтобы получить данные в песочнице. Давайте посмотрим на порядок статистического анализа ниже.

Статистический анализ
Вы можете использовать R для очистки, преобразования и визуализации данных. Это поможет вам выявить выбросы и установить связь между переменными. После того, как вы очистили и подготовили данные, пришло время сделать исследовательскую аналитику. Давайте посмотрим, как вы можете этого достичь.
Фаза 3 — Планирование модели: Здесь вы определяете методы и техники для выявления отношений между переменными. Эти отношения задают основу для алгоритмов, которые вы будете реализовывать на следующем этапе. Вы будете применять Explorative Data Analytics (EDA), используя различные статистические формулы и инструменты визуализации.
Давайте посмотрим на различные инструменты планирования модели.
? №1. Профессия Data Scientist от Skillbox
После прохождения этого курса ты освоишь 2 специальности и получишь 1.5 года реального стажа в Data Science.

Кому подойдёт:
- Новичкам в IT. Чтобы получить базовые навыки программирования, аналитики и математики.
- Программистам. Для улучшения своих знаний и навыков в Python и R.
- Аналитикам. После обучения ты научишься ставить гипотезы, кодить на Python и R, а также повысишь свою квалификацию.
Чему научат:
- Навыкам в аналитике.
- Базовым знаниям по математике для DS.
- Работе с языками Python и R.
- Методам визуализации данных.
- Взаимодействию с базами данных.
- Использованию нейронных сетей и построению рекомендательных систем.
Сколько длится: 18 месяцев.
Цена: 232 500 рублей без скидки, 116 250 рублей со скидкой
Плюсы и минусы профессии
Плюсы
- Профессия не только чрезвычайно востребованная, но существует острый дефицит специалистов такого уровня. Поэтому так стремительно и широко финансируются и развиваются факультеты при самых престижных вузах по подготовке специалистов по данным. В России также растет спрос на Data Scientist.
- Высокооплачиваемая профессия.
- Необходимость постоянно развиваться, идти в ногу с развитием IT-технологий, самому создавать новые методы обработки, анализа и хранения данных.
Минусы
- Не каждый человек сможет освоить эту профессию, нужен особый склад ума.
- В процессе работы могут не сработать известные методы и более 60% идей. Множество решений окажется несостоятельным и нужно иметь большое терпение, чтобы получить удовлетворительные результаты. Учёный не имеет права сказать: «НЕТ!» проблеме. Он должен найти способ, который поможет решить поставленную задачу.
Этап 6
Углубление и развитие технических навыков
Если предыдущие этапы давали вам навыки, без которых работать ну вообще нельзя, то навыки этого этапа призваны повысить вашу продуктивность или повысить качество решаемых задач, повысить самостоятельность при запуске разработанных моделей машинного обучения в продакшн.
-
Python на хорошем уровне: декораторы, уверенное знание классов и наследования, изучение базовых классов, dunderscore __методы__ .
-
Уверенное пользование bash, понимание основ linux
-
Полезно изучить основы docker
Все эти вещи можно было бы учить и раньше. Но, как правило, раньше их знать просто не нужно. Т.к. вы больше будете страдать от нехватки других навыков, приведенных в предыдущих этапах.
Другие области машинного обучения
В какой-то момент вам может потребоваться выйти из сферы подготовки прогнозных моделей или изучения и объяснения данных (кластеризация, EDA и визуализация). Это может быть связано как с вашими интересами, так и с проектами на работе. Например, это могут быть рекомендательные системы. Наверное, базовые рекомендательные алгоритмы можно изучать и одновременно с основами машинного обучения, т.к. знание одного не является обязательным для знания другого. Но логичнее переходить к ним, когда вы уже разобрались с основными алгоритмами обучения прогнозирования и кластеризации: скорее всего, этого от вас будут ожидать любые коллеги до тех пор, как вы включитесь в работу над рекомендательными системами.
Нейронные сети
Начиная с этого этапа имеет смысл изучать нейронные сети как следует с тем, чтобы применять их на пратике. Неэффективно изучать их раньше, т.к. многие задачи эффективно можно решить другими методами. И пока ваши данные и прогнозы изначально числовые, обычно «классическими» методами их решать эффективнее.
Подробнее в этапы изучениях нейронных сетей вдаваться не стану: эта тема требует отдельной статьи. И потратить на них можно от 50, чтобы решать самые простейшие задачи, до сотен часов, чтобы решать задачи связанные с обработкой неструктурированных данных или с обучением сложных моделей.
Машинное Обучение
Цитируя Тома Митчела: Машинное обучения изучает вопрос создания программ, способных улучшаться в процессе обучения.
Машинное Обучение носит междисциплинарный характер и использует, среди прочего, методы из области информатики, статистики и искусственного интеллекта.
Основной областью исследований в Машинном Обучении являются алгоритмы, которые способны обучаться и запоминать и могут применяться в различных областях науки и бизнеса.
Курс
Data Scientist с нуля
Cтаньте дата-сайентистом и приручите большие данные. Вы научитесь выявлять закономерности в данных и создавать модели для решения реальных бизнес-задач. Скидка 5% по промокоду BLOG.
Узнать больше
Как мы отбирали курсы?
При выборе мы руководствовались такими критериями:
Польза и актуальность знаний. Изучали программу курса, чтобы понять, насколько полные и актуальные знания по профессии она дает.
Ценовая политика
В этой сфере стоят достаточно дорого, поэтому нам было особенно важно выделить школы, которые предлагают рассрочку, скидки, программы лояльности.
Политика в отношении трудоустройства
Мы понимаем, что потратить несколько лет и большой бюджет на образование и потом не найти работу – это серьезное разочарование, поэтому уделяем внимание тому, как школы содействуют трудоустройству выпускников.
Отзывы студентов. Обязательно учитываем опыт предыдущих учеников.
Дополнительные возможности: бонусные курсы, работа над гибкими навыками.
Диплом
Насколько ценен документ об окончании курса, имеет ли он государственную лицензию.
Квалификация лекторов
Для нас важно, чтобы преподаватели не просто пересказывали теорию, а понимали, как работает индустрия изнутри и давали студентам реальные знания и навыки, которые пригодятся в профессии.
Чем отличается аналитик Big Data от исследователя данных
На первый взгляд может показаться, что Data Scientist ничем не отличается от Data Analyst, ведь их рабочие обязанности и профессиональные компетенции частично пересекаются. Однако, это не совсем взаимозаменяемые специальности. При значительном сходстве, отличия между ними также весьма существенные:
- по инструментарию – аналитик чаще всего работает с ETL-хранилищами и витринами данных, тогда как исследователь взаимодействует с Big Data системами хранения и обработки информации (стек Apache Hadoop, NoSQL-базы данных и т.д.), а также статистическими пакетами (R-studio, Matlab и пр.);
- по методам исследований – Data Analyst чаще использует методы системного анализа и бизнес-аналитики, тогда как Data Scientist, в основном, работает с математическими средствами Computer Science (модели и алгоритмы машинного обучения, а также другие разделы искусственного интеллекта);
- по зарплате – на рынке труда Data Scientist стоит чуть выше, чем Data Analyst (100-200 т.р. против 80-150 т.р., по данным рекрутингового портала HeadHunter в августе 2019 г.). Возможно, это связано с более высоким порогом входа в профессию: исследователь по данным обладает навыками программирования, тогда как Data Analyst, в основном, работает с уже готовыми SQL/ETL-средствами.
На практике в некоторых компаниях всю работу по данным, включая бизнес-аналитику и построение моделей Machine Learning выполняет один и тот же человек. Однако, в связи с популярностью T-модели компетенций ИТ-специалиста, при наличии широкого круга профессиональных знаний и умений предполагается экспертная концентрация в узкой предметной области. Поэтому сегодня все больше компаний стремятся разделять обязанности Data Analyst и Data Scientist, а также инженера по данным (Data Engineer) и администратора Big Data, о чем мы расскажем в следующих статьях.
Data Scientist – одна из самых востребованных профессий на современном ИТ-рынке
В области Big Data ученому по данным пригодятся практические знания по облачным вычислениям и инструментам машинного обучения. Эти и другие вопросы по исследованию данных мы рассматриваем на наших курсах обучения и повышения квалификации ИТ-специалистов в лицензированном учебном центре для руководителей, аналитиков, архитекторов, инженеров и исследователей Big Data в Москве:
- PYML: Машинное обучение на Python
- DPREP: Подготовка данных для Data Mining
- DSML: Машинное обучение в R
- DSAV: Анализ данных и визуализация в R
- AZURE: Машинное обучение на Microsoft Azure
Смотреть расписание
Записаться на курс
Образование в области Data Science: ничего невозможного нет
Сегодня для тех, кто хочет развиваться в сфере анализа больших данных, существует очень много возможностей: различные образовательные курсы, специализации и программы по data science на любой вкус и кошелек, найти подходящий для себя вариант не составит труда. С моими рекомендациями по курсам можно ознакомиться здесь.
Потому как Data Scientist — это человек, который знает математику. Анализ данных, технологии машинного обучения и Big Data – все эти технологии и области знаний используют базовую математику как свою основу.
Читайте по теме: 100 лучших онлайн-курсов от университетов Лиги плюща Многие считают, что математические дисциплины не особо нужны на практике. Но на самом деле это не так.
Приведу пример из нашего опыта. Мы в E-Contenta занимаемся рекомендательными системами. Программист может знать, что для решения задачи рекомендаций видео можно применить матричные разложения, знать библиотеку для любимого языка программирования, где это матричное разложение реализовано, но совершенно не понимать, как это работает и какие есть ограничения. Это приводит к тому, что метод применяется не оптимальным образом или вообще в тех местах, где он не должен применяться, снижая общее качество работы системы.
Хорошее понимание математических основ этих методов и знание их связи с реальными конкретными алгоритмами позволило бы избежать таких проблем.
Кстати, для обучения на различных профессиональных курсах и программах по Big Data зачастую требуется хорошая математическая подготовка.
«А если я не изучал математику или изучал ее так давно, что уже ничего и не помню»? — спросите вы. «Это вовсе не повод ставить на карьере Data Scientist крест и опускать руки», — отвечу я.
Есть немало вводных курсов и инструментов для новичков, позволяющих освежить или подтянуть знания по одной из вышеперечисленных дисциплин. Например, специально для тех, кто хотел бы приобрести знания математики и алгоритмов или освежить их, мы с коллегами разработали специальный курс GoTo Course. Программа включает в себя базовый курс высшей математики, теории вероятностей, алгоритмов и структур данных — это лекции и семинары от опытных практиков
Особое внимание отведено разборам применения теории в практических задачах из реальной жизни. Курс поможет подготовиться к изучению анализа данных и машинного обучения на продвинутом уровне и решению задач на собеседованиях
|
15 сентября в Москве состоится конференция по большим данным Big Data Conference. В программе — бизнес-кейсы, технические решения и научные достижения лучших специалистов в этой области. Приглашаем всех, кто заинтересован в работе с большими данными и хочет их применять в реальном бизнесе. |
Ну а если вы еще не определились, хотите ли заниматься анализом данных и хотели бы для начала оценить свои перспективы в этой профессии, попробуйте почитать специальную литературу, блоги о науке данных или посмотреть лекции. Например, рекомендую почитать хабы по темам Data Mining и Big Data на Habrahabr. Для тех, кто уже хоть немного в теме, со своей стороны порекомендую книгу «Машинное обучение. Наука и искусство построения алгоритмов, которые извлекают знания из данных» Петера Флаха — это одна из немногих книг по машинному обучению на русском языке.
Заниматься Data Science так же трудно, как заниматься наукой в целом. В этой профессии нужно уметь строить гипотезы, ставить вопросы и находить ответы на них. Само слово scientist подталкивает к выводу, что такой специалист должен, прежде всего, быть исследователем, человеком с аналитическим складом ума, способный делать обоснованные выводы из огромных массивов информации в достаточно сжатые строки. Скрупулезный, внимательный, точный — чаще всего он одновременно и программист, и математик.
Где используется Data Science?
- Как насчет того, сможете ли вы понять точные требования своих клиентов к существующим данным, таким как история просмотра посетителей, история покупок, возраст и доход. Без сомнения, у вас были все эти данные ранее, но теперь с огромным количеством и разнообразием их вы можете более эффективно обучать модели и рекомендовать продукт своим клиентам с большей точностью. Разве это не удивительно, поскольку это принесет больше преимуществ вашей организации?
- Давайте рассмотрим другой сценарий, чтобы понять роль Data Science в принятии решений. Как насчет того, если ваш автомобиль использовал элементы ИИ чтобы отвезти вас домой? Автопилот собирает данные от датчиков, радаров, камер и лазеров, чтобы создать карту окружения. Основываясь на этих данных, он принимает решения, например, когда ускоряться, когда нужно обгонять, где нужно сделать чередование с использованием передовых алгоритмов машинного обучения.
- Давайте посмотрим, как Data Science может использоваться в интеллектуальной аналитике. Рассмотрим пример прогнозирования погоды. Данные о кораблях, самолетах, радарах, спутниках могут собираться и анализироваться для создания моделей. Эти модели не только прогнозируют погоду, но также помогают прогнозировать возникновение любых стихийных бедствий. Это поможет вам заранее принять необходимые меры и спасти много драгоценных жизней.
Посмотрим на нижеприведенную инфографику, чтобы увидеть все области, где Data Science производит впечатляющие результаты.

В каких областях Data Science поражает воображение
Теперь, когда вы поняли необходимость в Data Science, давайте поймем, что это такое.
Вывод изображения
D3.js — чрезвычайно мощная библиотека функций графического отображения данных. С функциями библиотеки работать довольно сложно, и, возможно, кому-то они покажутся трудными для понимания, но это лучший вариант с открытым исходным кодом, который мне удалось найти для вывода графики на серверной части. Больше всего в библиотеке D3.js мне импонирует то, что она может работать с изображениями SVG. D3.js была разработана для запуска в веб-браузере, поэтому предполагается, что она должна работать с определённой веб-страницей. Работа на серверной части выполняется совсем в другой среде, поэтому работать придётся с виртуальной веб-страницей. К счастью, к нашим услугам пакет D3-Node, предельно упрощающий весь процесс.
Начните с определения некоторых важных количественных параметров, которые потребуются в дальнейшем:
Вам предстоит преобразовать координаты данных в координаты графика (изображения). Для такого преобразования можно использовать шкалы: область шкалы — это пространство данных, в котором выбираются точки данных, а диапазон шкалы — это пространство изображения, где помещаются точки:
Обратите внимание, что диапазон шкалы y инвертирован, так как в стандарте SVG начало шкалы y располагается сверху. После определения шкал начинайте рисовать график на только что созданном изображении SVG:. Вначале нарисуйте интерполирующую линию, добавив к изображению SVG элемент line:
Вначале нарисуйте интерполирующую линию, добавив к изображению SVG элемент line:
Затем для всех точек данных в нужных местах добавьте элемент circle. Главной особенностью библиотеки D3.js является то, что она связывает данные с элементами SVG, для этого воспользуйтесь методом data(). Метод enter() сообщает библиотеке, какие именно действия выполнять с новыми связанными данными:
Последние выводимые на изображение элементы — это оси с соответствующими метками; они выводятся как наложение на линии и окружности графика:
И последнее действие — сохранение графика в файл SVG. Я выбрал вариант синхронной записи файла, чтобы продемонстрировать работу второго подхода:
Результаты
Запуск скрипта предельно прост:
Результат его выполнения:
Вот результирующее изображение, созданное мной с помощью библиотек D3.js и Node.js:



